
DSP中的基础算法和模型的详细解析
美国有一家很优秀的DSP公司–M6D(m6d.com),这个公司只是个startup公司,却已经在KDD之类的顶级会议发表的7-8篇优秀的文章。最近我研究了一下他们的DSP算法,和大家分享一下我的理解,希望以一个实例让大家对DSP中的基础算法和模型有一个初步的了解。写得不对的地方,还请大家及时指正。 原文出处 SEM优化网 www.semyouhua.com
这篇文章假设大家对DSP及RTB生态圈各种三个字母缩写的概念有初步的理解。 尊重原创 SEM优化网 www.semyouhua.com
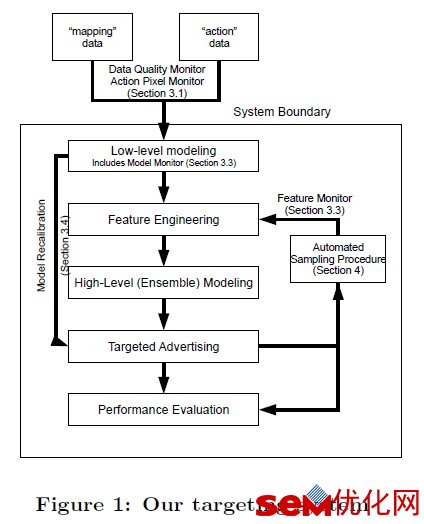
一、整体流程首先,我们先来看一下M6D的DSP工作的整个流程: 本文来自 SEM优化网 www.semyouhua.com
追踪用户行为:DSP公司通常会在广告主的网站上埋点(即放上一个1×1的不可见像素),这样当互联网用户第一次访问广告主的网站时,就会得到DSP公司的一个cookie,这样DSP公司就可以追踪到这个网民的在广告主网站上的行为了(这些数据也叫action data)。DSP公司还会和第三方的网站合作(例如:新浪,腾讯),在他们的网站上也埋点,或者向DMP购买网民行为数据,这样就可以追踪到网民在这些网站上的行为了(这些数据也叫mapping data)。这里值得一提的是,DSP公司对某一个用户记录的cookie和第三方网站或DMP或exchange记录的cookie是不一样的,这里需要一个叫Cookie Mapping的过程,这不是本文重点,以下假设DSP已经做好了Cookie Mapping,每个用户有一个唯一的id标识。
受众选择(audience selection):m6d对每一个Compaign(即每一个广告主的每个推广活动), 训练一个audience selection model, 该模型以在广告主的网站上发生转化行为(转化行为可以是注册成为用户,点击某个特定页面,购买产品。每个广告主对转化的定义不一样)的用户为正例,没有发生转化行为的用户为负例(是的,正负例很不均匀,通常要做采样和结果修正)。得到模型后,对所有的用户预估对这个compaign的转化概率p(c | u),即该用户u有多大的概率会在广告主的网站上发生转化行为(c表示conversion),去掉大多数转化概率非常小的用户,将目标用户根据转化概率高低分到不同的segments中。这样我们对每个compaign就找到了很多的目标用户,而且这些用户根据他们的质量高低,被分别放在不同的segments中。 本文来自 SEM优化网 www.semyouhua.com
通知exchange:DSP将这些目标用户的cookie告诉exchange,这样当有这些cookie的请求来的时候,exchange才会来向DSP的服务器发送请求。
原文出处 SEM优化网 www.semyouhua.com
Segment管理:通常DSP公司会有账户管理员(运营人员),他们人工来对每个compaign的做一些设定。他们根据每个compaign所属的行业特点,经济状况,决定开启哪些segments,关掉哪些segments。例如:对没钱的小公司的compaign, 那些用户转化概率小一些的segment就不要投广告了。他们还需要对每个segment设定一个基础出价(base price)。账户管理员可以拿到每个segment的平均预估转化概率,来辅助他们设定基础出价。这一步也是人工影响投放策略最主要的地方。
本文来自 SEM优化网 www.semyouhua.com
进行实时竞价:当exchange把请求发过来的时候,DSP会拿到以下信息:当前广告位的信息,当前用户的cookie和基本信息。DSP需要在100ms内,根据对当前用户的理解,并且考虑当前广告位,根据自己的bidding算法,来要决定是否要买这次展现,投放哪个compaign的广告,出价是多少(bidding),并向exchange返回出价信息?如果超过时间DSP没有响应,则exchange默认DSP放弃这次竞价。 本文来自 SEM优化网 www.semyouhua.com
展现广告:如果赢得了展现机会,则DSP返回创意,用户就会在该广告位看到该创意。
原文出处 SEM优化网 www.semyouhua.com
追踪转化:因为DSP在广告主的网站上埋了点,就能知道用户是否在这次展现之后进行了转化行为。根据这些数据统计转化率,每个转化平均成本等指标,汇总成报告给广告主。
本文来自 SEM优化网 www.semyouhua.com
二、核心算法第2步(Audience Selection)和第5步(Bidding)是最核心的两步,其中audience selection是离线计算过程,因为可以在exchange发送请求前离线慢慢算好,而bidding的过程需要在100ms内在线快速算好。下面分开介绍这两步中的算法和模型,最后介绍如何对算法效果进行评估。
Audicence Selection:
本文来自 SEM优化网 www.semyouhua.com
m6d的Audience Selection算法需要对每个compaign都训练以下两个模型(对每个compaign独立训练模型是因为广告主隐私保护,从一个广告主网站上采集的数据不能用来优化另外一个广告主的模型,例如不能利用京东上访问过电视购买页面的用户数据,来给苏宁电器优化模型,被京东知道了,他们的生意你以后就没得做了。另外一个原因是分每个compaign单独训练模型在训练数据充足的时候可能有更优的效果。当然隐私的原因是主要原因):
Low-level Model:这个模型的作用是做初选。所有在该compaign对应的广告主网站上发生转化行为的用户作为正例,其他的用户作为负例(即利用action data)。该模型的特征只有一类,就是用户历史访问过的URL(即利用mapping data)。也就是说,所有可能的URL数就是特征空间的维数,如果用户访问过某个URL,那么这个URL对应的那一维特征的取值就是1,否则就是0. 显而易见,这样会导致特征空间维数太大,所以要做一个最基本的特征选择:去掉那些覆盖用户的转化总数小于某个固定的转化数阈值(比如5)的特征(具体做的时候可以用展现数过滤,阈值设为 转化数阈值/平均转化率)。这样会显著减少特征的数量。即使大幅减少了特征,但数目还是很多,所以这个模型m6d不意外地用了线性模型。
本文来自 SEM优化网 www.semyouhua.com
High-level Model: 这个模型的作用是细选。模型的样本和Low-level Model一样,特征就不限于用户访问过的URL了,可以是这个用户的各种挖掘出来的属性标签,包括可解释的分类标签,不可解释的聚类id, topic id,与广告主网站的关联特征等。这里也就是用户属性标签(user profile)起作用最重要的地方了,给用户打标签的技术是很多广告公司的基本功,这里就不着重介绍了。有意思的是,m6d还用了Low-level Model的输出值作为特征之一。这个模型m6d还是选择了线性模型,但因为这个模型要预测的样本数比较少了,可以做一些复杂的计算。m6d选择了一个非线性模型(Generalized additive model with smoothing splines)对结果进行修正。 尊重原创 SEM优化网 www.semyouhua.com
之所以要分为两个模型,个人认为主要是性能考虑,如果把所有的用户都用high-level model来预测,那么在特征抽取和预测上都会消耗大量的计算量。而low-level模型因为特征只有URL,特征抽取逻辑简单,计算量小很多,另外对于一个compaign的Low-level Model来说,非0权重的特征数目有限,只需要把这些非0权重的url对应的用户拿出来计算预估值就可以了(相当于一个简单检索过程),不需要对所有的用户来计算预估值。 尊重原创 SEM优化网 www.semyouhua.com
本文来自 SEM优化网 www.semyouhua.com
尊重原创 SEM优化网 www.semyouhua.com
之后,每个compaign就会根据每个用户通过audience selection model预估的转化概率p(c|u)选出目标用户,m6d的经验数据是不超过百分之一的用户会成为某个compaign的目标用户。然后这些目标用户会根据不同的转化概率阈值划分到不同的segments中。例如p(c|u)>0.01放到一个segment中,0.01>= p(c|u) > 0.001放到另外一个segment中。论文中没有说到一个用户是否可以放到两个或以上的segment中,但我觉得应该是可以的。每个compaign有大约10到50个segments左右。划分segments的作用一是方便账户管理员对每个segment设置基础出价,另外在后面介绍的bidding算法中将属于同一个segment的用户做无差别对待,相当于同属一个类,可以缓解某些用户数据稀疏的问题,后面会详细介绍。 原文出处 SEM优化网 www.semyouhua.com
以上就是m6d的audience selection算法,值得注意的是,上述步骤是offline的,也即是预处理的,在exchange的请求到来前就已经对每个compaign都算好了。有的地方把根据广告主的一些少量已知转化用户找到更多潜在用户的模型叫做Look-alike Model, 我理解这里的audience selection model也应该算是look-alike model。
尊重原创 SEM优化网 www.semyouhua.com
Bidding当exchange发送请求时,DSP会接受到当前用户的cookie和一些最基本的用户信息,以及当前广告位的信息。DSP则需要找到这个用户所属的所有segments,而这些segments可能会对应多个compaign。那么应该出哪个compaign的广告呢?这里有一个内部竞价的过程。
原文出处 SEM优化网 www.semyouhua.com
m6d是这么做的,首先要把一些不合适出广告的compaign根据规则过去掉。主要的规则有,如果一个用户之前已经被展现了这个compaign的广告数达到一定的个数了,那么就不要再浪费广告费了(这个次数限制通常叫frequency cap)。另外一个主要规则是,如果一个compaign已经达到了它的每日,或者每周,或者每月预算限制了,那么也不再为它投放广告了。对于剩下的compaign候选,DSP会对他们都根据算法计算出最合适的出价,然后简单地选取出价最高的那个(出价反映了当前用户对该compaign的价值)。细心的朋友会发现这里是一个贪心的算法,有优化的空间,这个我们最后一起来总结。 尊重原创 SEM优化网 www.semyouhua.com
下面介绍下对于某一个compaign, 如何计算对当前展现机会的出价。 本文来自 SEM优化网 www.semyouhua.com
前面的audience selection部分,我们已经对每个用户划分了segments,然后账户管理员又对每个segment给出了基础出价(base price),当时这个出价考虑的是这个用户和这个compaign的适合程度,并没有考虑当前广告位是否适合这个compaign投广告,是否适合这个用户。因此m6d的算法,以基础出价为基准,根据当前广告位计算出一个调整因子 Φ ,最后的出价就是 baseprice∗Φ 。因此我们全部的工作就是要计算这个 Φ 。 尊重原创 SEM优化网 www.semyouhua.com
如果上过刘鹏老师的计算广告学课的同学肯定会知道,在广义二阶竞价模型里,排序是应该按照 ecpm=转化概率*转化价值 来排序的。ecpm可以认为是一个展现的价值,它等于一个转化的价值*一个展现变为一个转化的概率。其实我想说的就是,对于同一个compaign来说,如果我们知道一个展现的转化率是另外一个展现的2倍,那么前面那个展现的出价应该是后面那个展现的出价的2倍。
按照上面的逻辑,既然我们为segments出了一个平均价格base price,当仅当一个展现的转化率是这个segments中用户的平均转化率的 Φ 倍,我们应该为这个展现出 baseprice∗Φ 的出价。所以 尊重原创 SEM优化网 www.semyouhua.com
Φ=p(c|u,i)Ej[p(c|u,j)] 原文出处 SEM优化网 www.semyouhua.com
其中,u指的是用户,i是当前的广告位(inventory),c指的是转化。分母计算的是在所有广告位(用j指代)上的平均转化率。这个分母要计算起来很复杂,我们要遍历所有的广告位(inventory)。但我们知道:
原文出处 SEM优化网 www.semyouhua.com
p(c|u)=Ej[p(c|u,j)]=∑jp(c|u,j)p(j)
尊重原创 SEM优化网 www.semyouhua.com
因此有 尊重原创 SEM优化网 www.semyouhua.com
Φ=p(c|u,i)p(c|u) 本文来自 SEM优化网 www.semyouhua.com
所以m6d的bidding算法的最核心部分,就是为每个compaign都建立两个模型来分别预估p(c|u,i)和p(c|u)。考虑到每个compaign的转化数据很少,这2个模型的训练数据很少,要训练这两个模型太难了。因此m6d将同一个segment中的用户不做区分,从而可以把上式变为
原文出处 SEM优化网 www.semyouhua.com
Φ=p(c|s,i)p(c|s)
原文出处 SEM优化网 www.semyouhua.com
其中,s是segment。这样就只需要训练p(c|s,i)和p(c|s)。因为s的个数远小于u的个数,这2个模型的特征空间显著变小了,模型更容易得到更好的结果。事实上,m6d也对i的部分做了类似的trick,它把类似的广告位聚合到一起,给予一个相同的inventory id。目的和把u变为s是类似的。m6d的inventories的规模是5000个左右,每个compaign的segment的个数是10到50个左右。
以上就是m6d对bidding的建模过程了,剩下的工作就是如何训练得到这两个模型。
尊重原创 SEM优化网 www.semyouhua.com
p(c|s,i)模型: 要得到这个模型的训练数据,还有一个冷启动的过程。必须事先对这些segments在这些inventories上投放,然后把那些最终带来转化的展现标记为正例,没有最终带来转化的展现标记为负例。m6d认为一次转化是由之前7天内该用户见到的最后一次展现带来的。这个模型的特征只有两类,一类就是segment id, 另外一类就是inventory id。也就是说,每一个样本只有两个非0的特征,一个是segment id对应的那个特征,另外一个是inventory id对应的那个特征。m6d没有组合segment和inventory特征,这样做的结果是:不管对于哪个segment,某个特定的inventory对最后预估值的贡献都是一样的。这个假设可以认为在大多数情况下是合理的。而且如果真要把这些组合特征加入模型,特征空间一下子又大了不少,对于少得可怜的训练数据来说,很容易就过拟合了。 尊重原创 SEM优化网 www.semyouhua.com
p(c|s)模型:和p(c|s,i)模型基本一样,区别就是特征只有segment id。
本文来自 SEM优化网 www.semyouhua.com
这两个模型的正例比例都非常低,因此进行了采样(sampling)和修正(recalibration)。这是一种很常见的处理方式,不了解的朋友可以Google这篇文章:《Logistic regression in rare events》。
尊重原创 SEM优化网 www.semyouhua.com
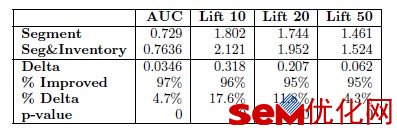
考虑了广告位(inventory)和不考虑广告位对转化率的预估由有多大的影响呢?以下的图展示了区别: 原文出处 SEM优化网 www.semyouhua.com
尊重原创 SEM优化网 www.semyouhua.com
本文来自 SEM优化网 www.semyouhua.com
考虑广告位信息后,AUC提升了0.0346,还是非常明显的。这个Lift也是一种评估指标,后面会详细解释。这里可以看到Lift指标也明显提升了。 原文出处 SEM优化网 www.semyouhua.com
(微信公众号:gmwlyxbj) 转载请注明出处:http://www.semyouhua.com/fenxi/1549.html- 上一篇:竞价数据波动较大怎么分析
- 下一篇:6个维度分析,如何正确地进行信息流广告投放?
相关阅读: